Datenintegration mit Data Virtualization
In fast allen Projekten ist Datenintegration ein Thema, das angegangen werden muss. Legacy Systeme, Daten aus verschiedenen Fachbereichen und sogar Daten, die per Datei ausgetauscht werden, müssen konsolidiert und kombiniert werden.
Probleme des klassischen Ansatzes
Für die Datenbereinigung und die Integration der Daten werden klassischerweise ETL-Jobs (extract, transform, load) verwendet. Ein meist nächtlicher Job lädt Daten aus den verschiedenen Quellen in eine Zieldatenbank. Diese Daten können dann für Reports, Dashboards und Anwendungen verwendet werden.
Dieser klassische Ansatz bringt mehrere Probleme mit sich. Einerseits sind die Daten bei ihrer Verwendung bereits wieder veraltet, denn ein Job, der eine große Menge an Daten lädt, lässt sich nicht beliebig oft an einem Tag ausführen. Andererseits werden oft auch viele Daten geladen, die gar nicht benötigt werden. Außerdem muss das Zusammenführen der Daten im ETL-Job händisch implementiert werden.
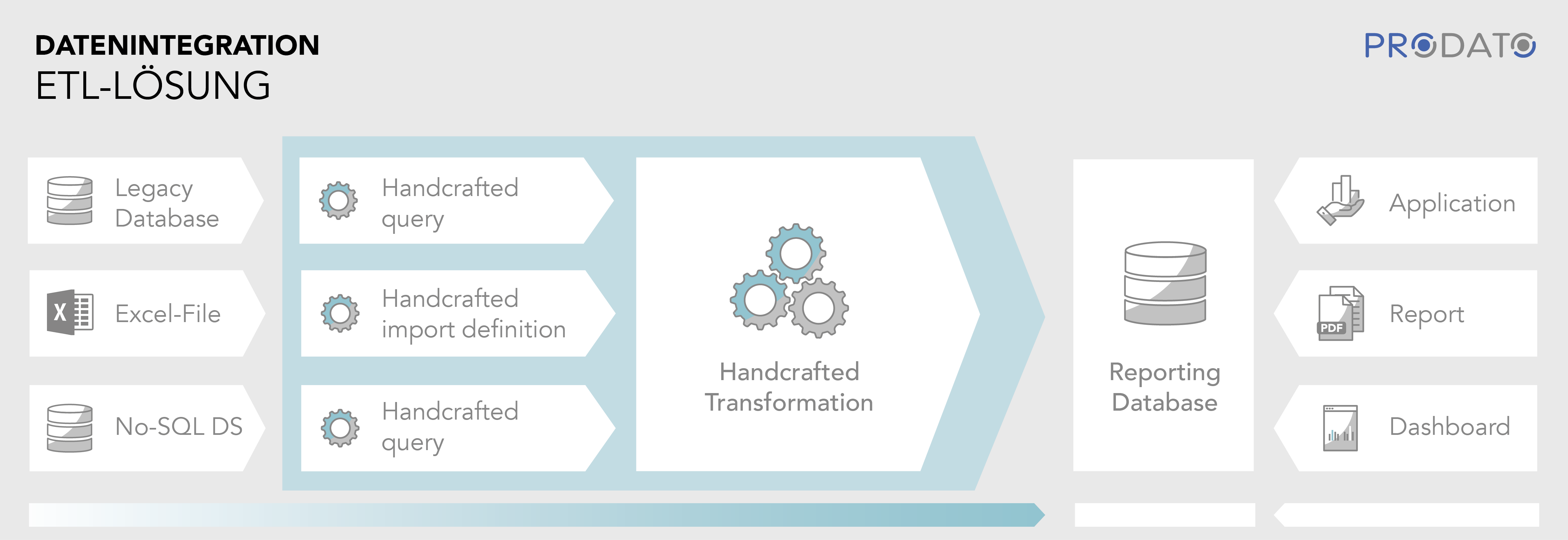
Eine mögliche Lösung für das Transferproblem ist das Laden von Deltas oder eine Integration via Push-Events, die aktuelle Informationen an interessierte Systeme verteilt. Dies ist aber nicht immer für alle beteiligten Quellsystem möglich und teilweise aufwendig zu implementieren.
Die Data Virtualization-Lösung
Data Virtualization dreht den Spieß um, indem die Daten nicht von den Quell-Systemen in das Zielsystem geladen werden, sondern vom Zielsystem bei Bedarf aus den Quell-Systemen angefragt werden. In einer Data Virtualization Engine (DVE) werden die Quell-Systeme (DBs, No-SQL DBs, Dateien) eingebunden und die Schemas der darin enthaltenen Daten extrahiert.
Auf diesen Schemas können dann Queries definiert werden, beispielsweise in SQL, durch die die Daten der Quellen auf die gewünschte Weise verbunden werden. Joins, Selektionsbedingungen und Aggregationen werden von der Data Virtualization Engine automatisch optimiert und wenn möglich an die Quellsysteme weitergereicht, so dass sie dort effizient ausgeführt werden können. Dazu nutzt die DVE Metadaten, die sie automatisch aus den Quellsystemen extrahieren kann. Dem Zielsystem werden die gewünschten Daten von der DVE als JDBC, REST oder Odata Datenquelle zur Verfügung gestellt.
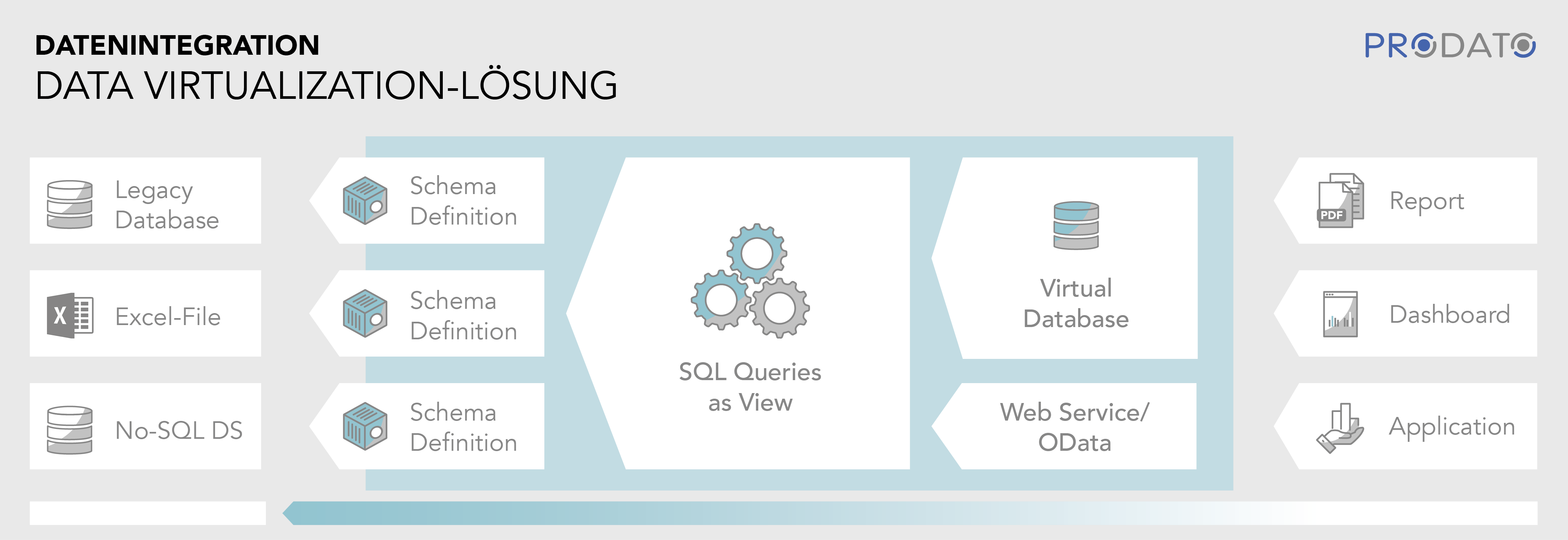
Die Implementierung einer Data-Virtualization-Lösung kann damit schneller erfolgen als eine vergleichbare ETL-Lösung, da nur SQL Views geschrieben werden müssen, anstatt der manuellen Entwicklung und Optimierung einer ETL-Strecke. Es müssen keine Delta-Lade-Mechanismen implementiert werden und auch eine Historisierung in der der Reporting DB ist nicht nötig, sofern alle Daten in den Quellsystemen bereits historisiert vorliegen.
Benötigt nun eine Anwendung, ein Dashboard oder ein Report Daten, kann es diese anfragen und bekommt eine ad hoc aus den Quellen integrierte Antwort. Auf diese Weise sind die Daten immer aktuell und es werden nur wirklich benötigte Daten geladen. Falls dies für manche Anwendungen nicht schnell genug geht, lässt sich auch Caching hinzuschalten, das häufig benötigte Daten zwischenspeichert.
Die Data Virtualization Engine bietet auch die Möglichkeit die Data Lineage, also die Herkunft der Daten zu verfolgen und zu visualisieren. Auf diese Weise können Fachanwender prüfen aus welchen Quellen sich die Daten zusammensetzen, die sie in ihren Anwendungen sehen.
Ein Repository von Quellen und Queries ermöglicht es einmal erstellte Data-Virtualization-Pfade für mehrere Anwendungen zu verwenden, so dass Report-, Dashboard- und Anwendungsentwickler mit geringem Aufwand auf bereits integrierte Datenquellen zugreifen können. Damit können die gleichen Daten in verschiedenen Sichten für verschiedene Konsumenten angeboten werden.
Data Virtualization ist also eine spannende Alternative zu ETL für Datenintegration, die aktuelle Daten sofort sichtbar werden lässt. Unser Team von Experten unterstützt dabei gerne in allen Fragestellungen rund um Data Virtualization.
